Governance Doesn't Scale by Default
2025 · Credo AI
The problem
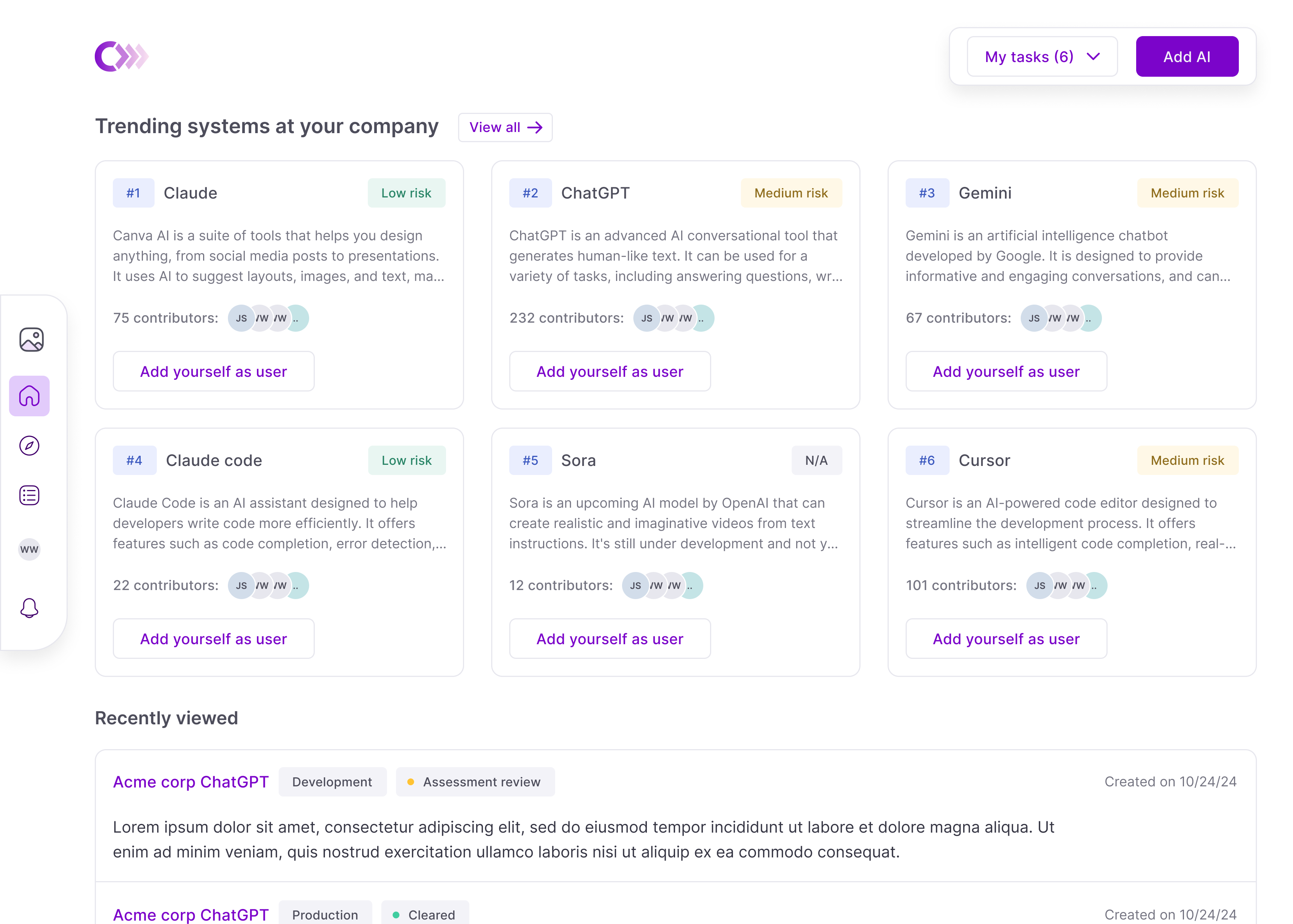
As AI adoption scaled, so did duplication. Teams registered the same tools under slightly different names, and a single tenant could accumulate 100+ duplicate use cases—each demanding its own review, ownership, and maintenance.
What looked like healthy adoption was fragmentation. Governance leads were buried in reviews, many of them duplicates or low-risk cases that shouldn't have reached them.
The cause was structural. Use cases, the primary governable entity, were private by default, so teams couldn't see what already existed.
Aligning the team
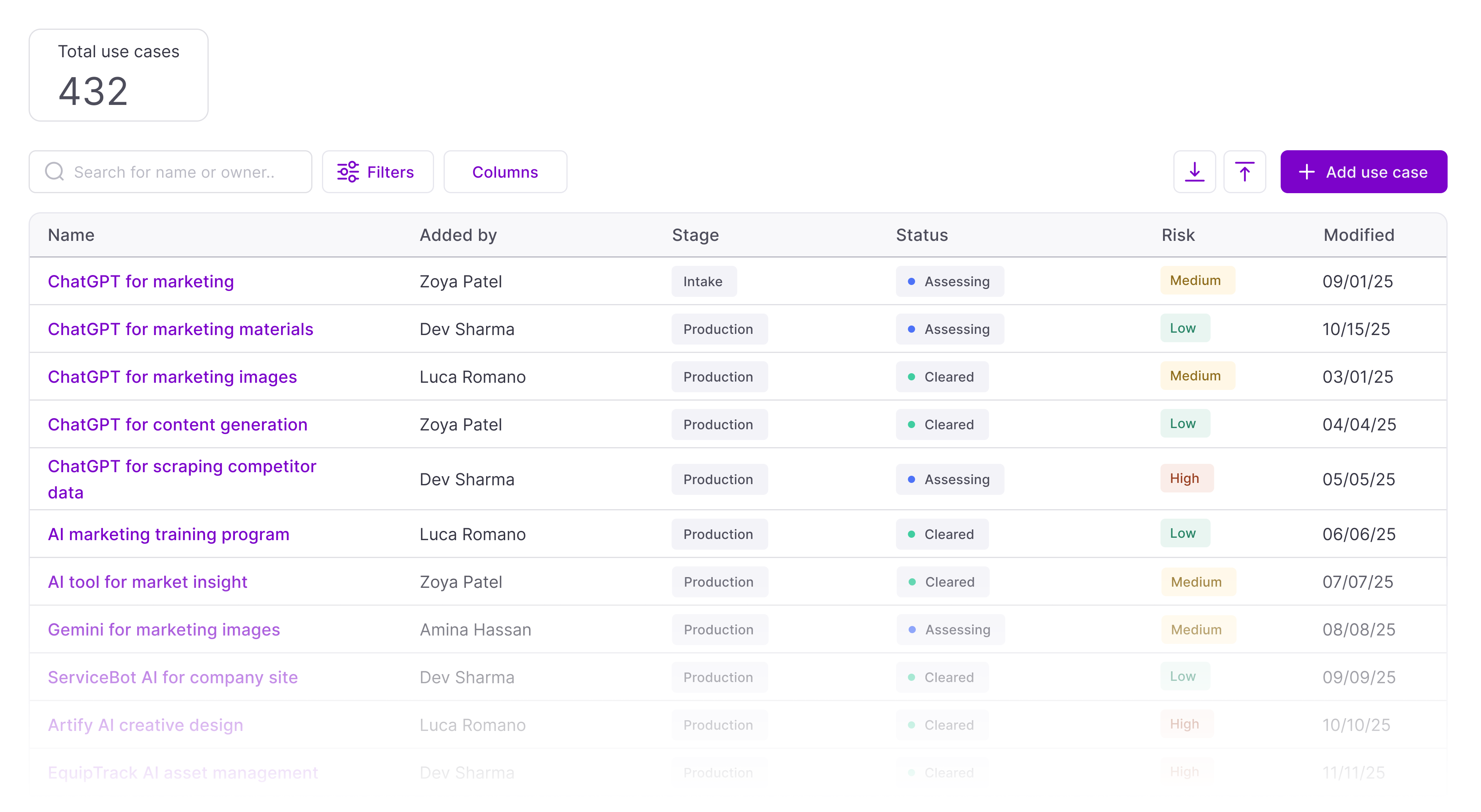
I drove alignment through artifacts: system diagrams, naming conventions, frameworks. Coining "governable entity" as internal shorthand reframed conversations from "which feature next" to "how do we evolve what can be governed."
I also led the sequencing: public use cases for visibility, acceptable use as a consolidation tool, AI assist to prevent duplication at entry. Each phase useful on its own, each enabling the next.
The entity issue
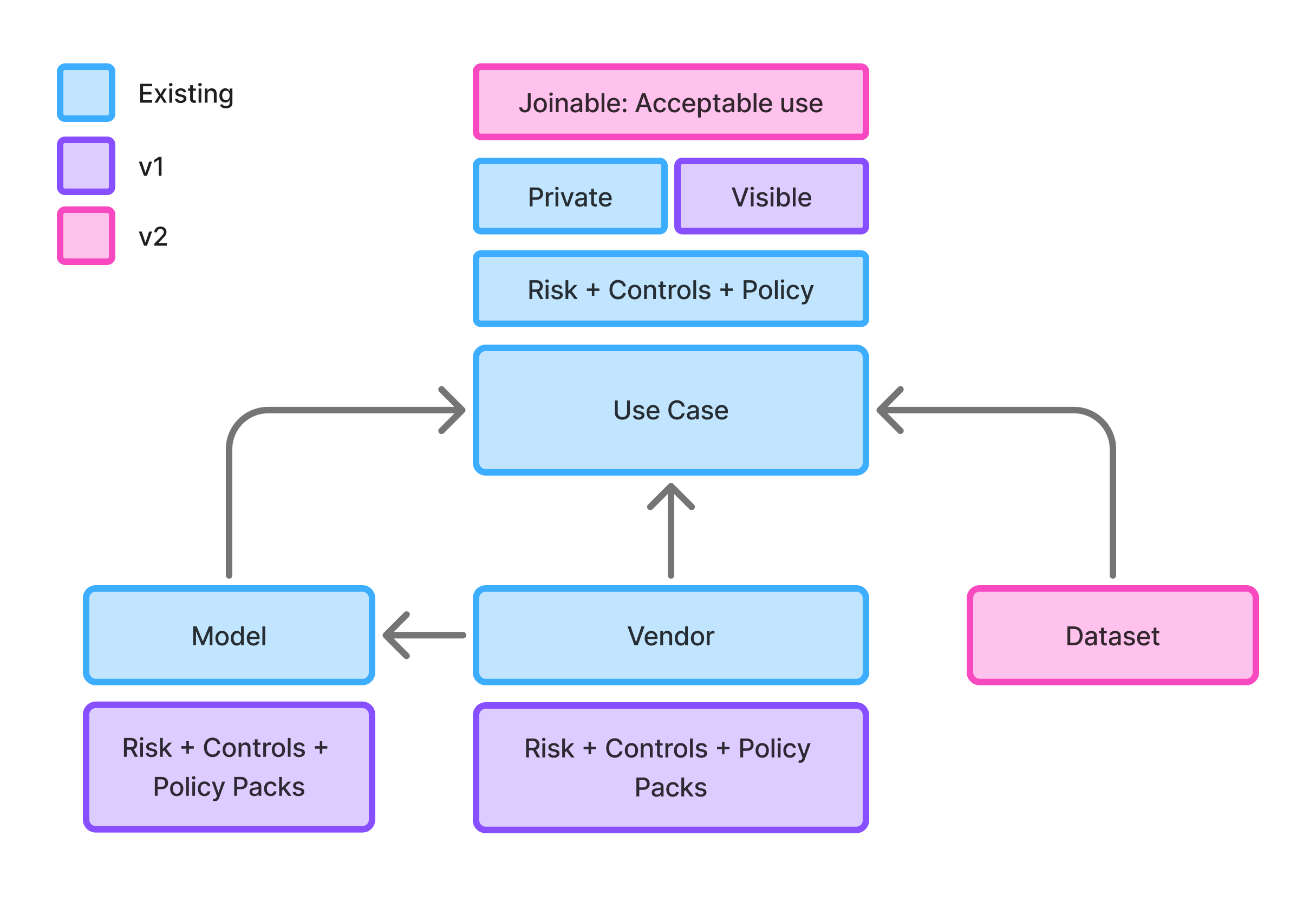
We explored governing at the model or vendor level instead, with a parent "Systems" entity connecting models, vendors, and use cases under one umbrella. Architecturally appealing, but AI usage was shifting every six months—rigid hierarchy on unstable adoption didn't pass the smell test. Design partners confirmed the opposite problem: a single model could power a low-risk summarizer and a customer-facing decision system.
Governing them identically was wrong.
The trade-off I argued for: keep the use case as the unit of governance, but make the system around it scalable. Ship incrementally—public use cases first, then acceptable use, then model and vendor governance as separate products.
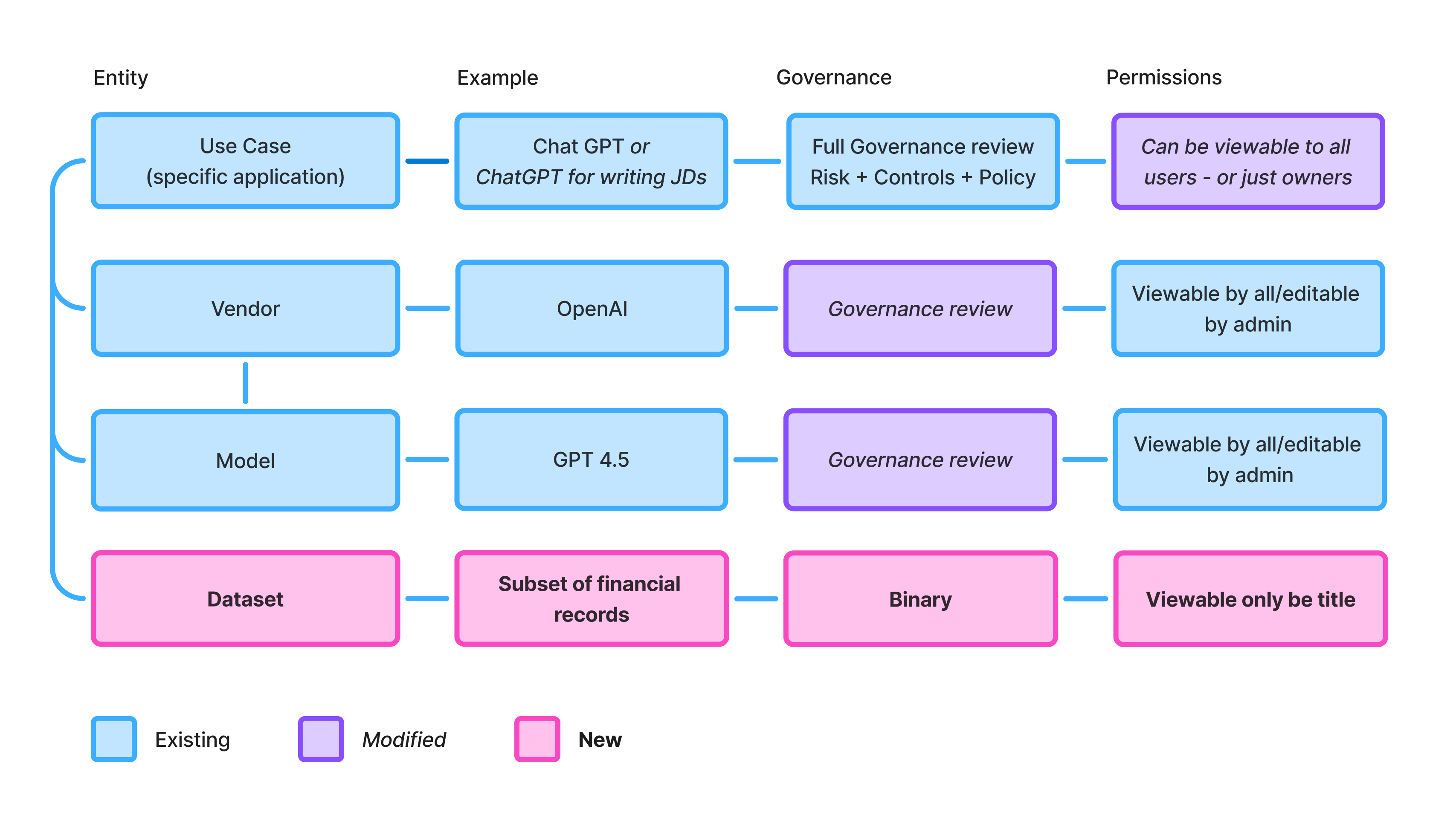
Opening use cases
Instead of registering a use case, a user can now find an existing use case, accept its terms, and add themselves. This collapsed the most common source of duplication: teams independently registering usage already governed elsewhere.
But public visibility meant rethinking permissions. Migrating existing use cases into new classifications was a non-starter at enterprise volume, so the model focused forward: promote new use cases as public, seed 10–15 low-risk ones to absorb the bulk of duplicates, keep sensitive use cases private.
Leveraging AI Assist
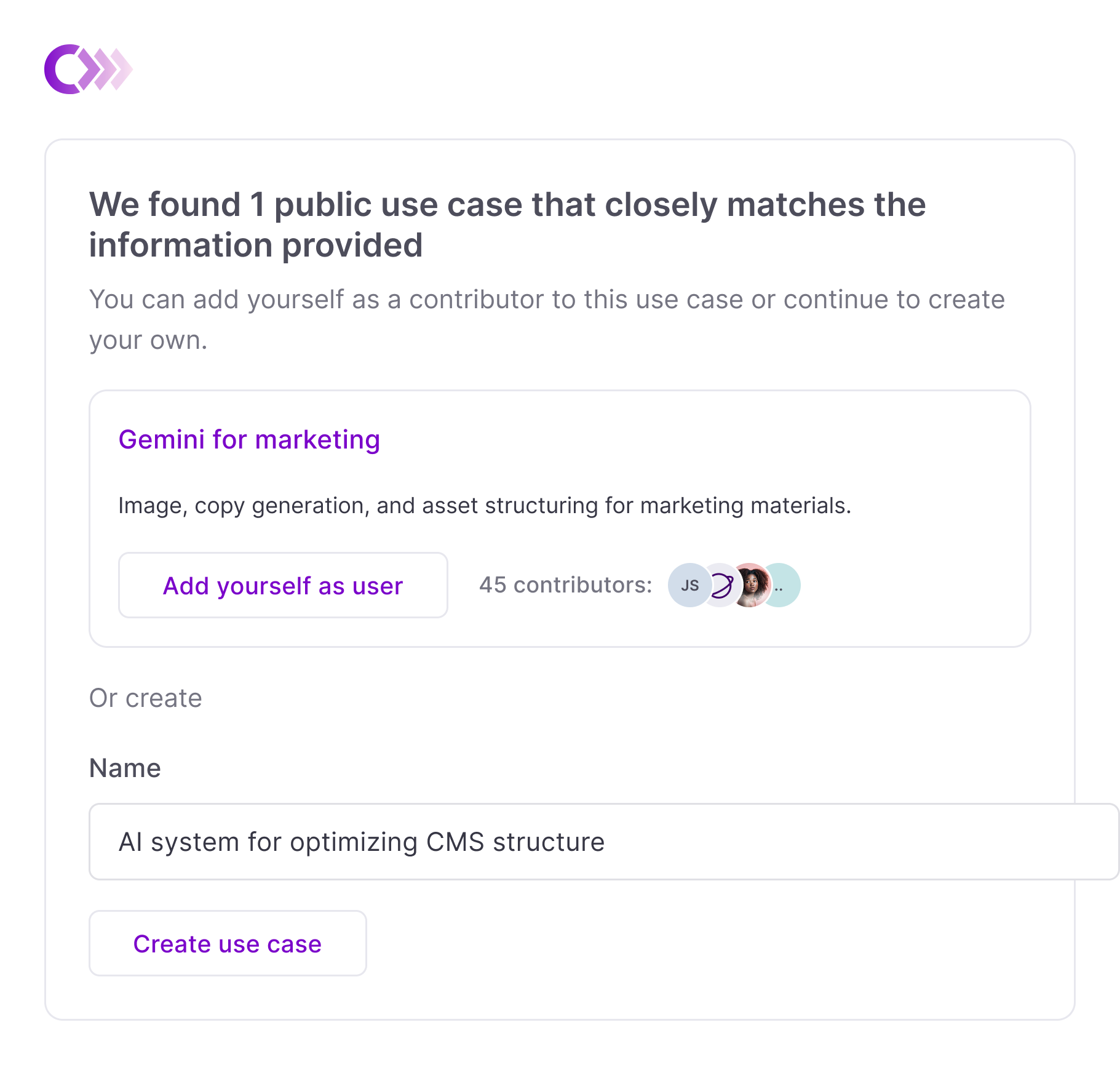
With public use cases and acceptable use in place, we could prevent duplication at the point of entry. AI assist reads registration inputs, searches the public database, and surfaces existing matches before a new use case is created.
I pushed for a conservative default: do not recommend unless there's a strong match. The public database would be too thin early on for anything beyond keyword-level matching. Bad recommendations would erode trust before the feature could prove itself.
Impact
This work was structural, not flashy. It didn't ship as a single feature with a clean before-and-after metric. It shipped as a sequence of changes that restructured how use cases are shared, joined, and consolidated.
Before this work, every new AI registration added governance overhead. After it, new registrations can resolve into existing governed entities, reducing review load, ownership fragmentation, and maintenance surface area.